CHAPTER 4. Pandas
1. Pandas란?
•
Pandas : python data anaylsis
•
Pandas 라이브러리에서 기본적으로 데이터를 다루는 단위는 DataFrame
(Spreadsheet 형태)
•
이러한 형태의 데이터는 Structured Data 또는 Panel Data 또는 Tabular Data라고 부름

2. Pandas의 기본 자료구조(Series, DataFrame)
•
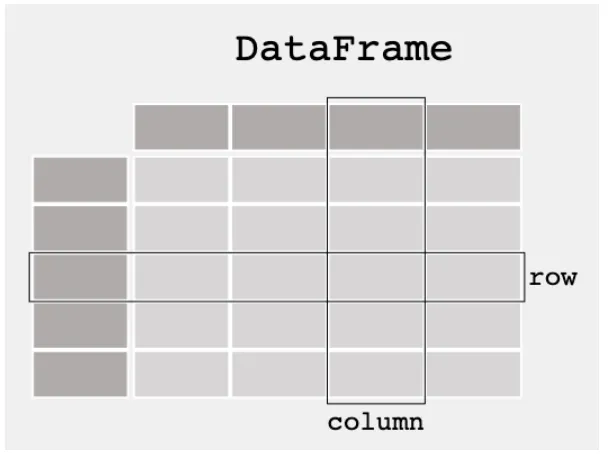
DataFrame은 2차원 테이블이고, 테이블의 한 줄(행/열)을 Series라고 함
→ Series의 모임이 곧, DataFrame
•
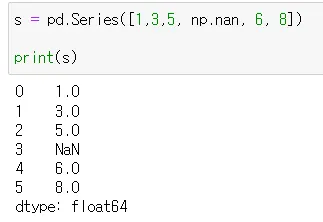
Series 기본 모양
•
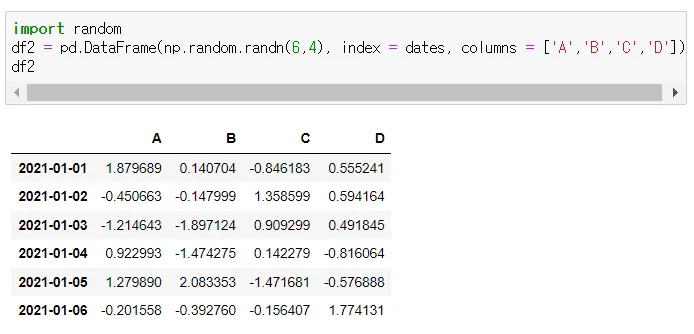
DataFrame의 기본 모양
◦
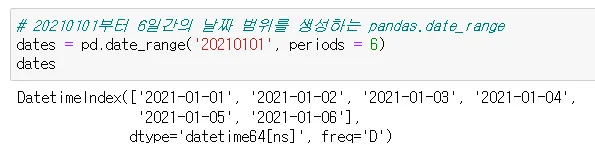
pd.date_range(’20210101’, periods = 6) 날짜 범위 생성
◦
pd.DataFrame(values, index, columns)
▪
index : 왼쪽
▪
columns: 위
3. DataFrame Method
•
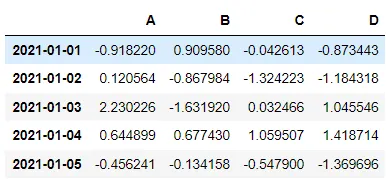
df2.head() → 맨 위 다섯줄을 보여줌, df2(head)(3) → 맨 위 세줄
df2.tail()은 밑에서부터
•
df.index → 인덱스를 확인

•
df.columns → 컬럼을 확인
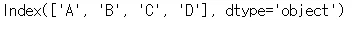
•
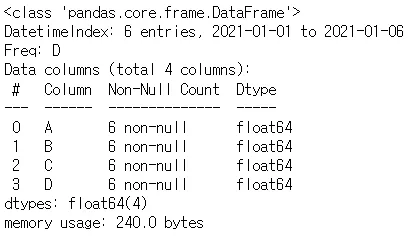
df.values → 값 확인
•
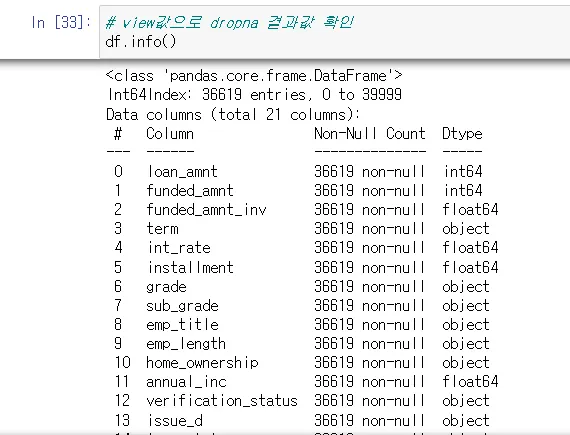
df.info()→ 대략적인 정보 확인
•
df.describe() → 전체적인 통계정보
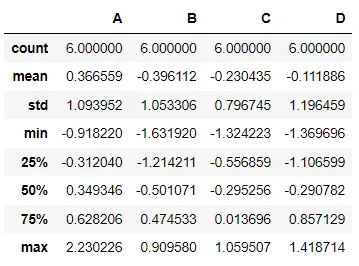
•
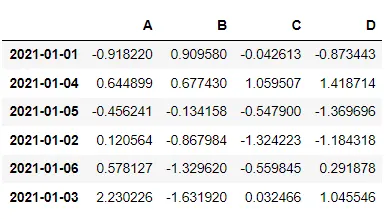
df2.sort_values(by = 'B', ascending = False) → B 컬럼을 기준으로 정렬(내림차순)
df2.sort_values(by = 'B', ascending = False).head(3) → B기준 제일 큰 값 세개
•
데이터 불러오기 read_csv()


→ 현재까지의 경로를 ./로 축약
•
데이터 저장하기
◦
o_csv()
◦
to_excel()
4. DataFrame Indexing
•
컬럼 기준딕셔너리
◦
df[’A’] 인덱싱
◦
df[[’loan,amnt’, ‘grade]] 여러 컬럼
•
로우 기준 시리즈
◦
인덱싱
▪
문자로 가져오기 df.loc[’2021-01-01’]
▪
인덱스 위치로 가져오기 df.iloc[2]
◦
슬라이싱
▪
위치 기준으로 df[:3]
▪
문자 기준으로 df[’2021-01-02’ : ‘2021-01-04’]
▪
df.iloc[:10:2, 2:3] → 처음부터 10번째까지, 둘 간격으로, 컬럼은 2:3
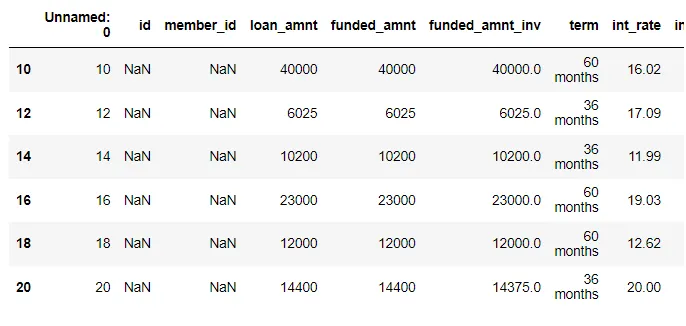
•
로우, 컬럼 함께
◦
df.loc[:, [’A’, ‘B’]]
◦
df.loc[’2021-01-03’:’2021-01-05’, [’A’,’B’]]
→ 물론 df.loc[’2021-01-02’, [’A’]] 인덱싱도 가능
◦
df.iloc[[1,2,4], [3,4]]
5. DataFrame 기타
•
DataFrame 복사
df3 = df.copy()
•
새로운 컬럼 추가하기
df2[’E’] = [’one, ‘one....]
인덱스 수랑 동일하게
딕셔너리랑 유사
key값을 따로 안쓰면 순서대로 들어감
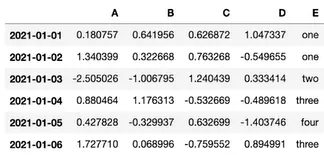
•
해당 항목이 있는지 확인
df2[’E’].isin([’two’, ‘four’])
two와 four이 있느냐
•
unique() 컬럼단위로 접근하고 각 컬럼의 고유값 출력(중복되지 않는 모든값)
•
nunique() 고유값 개수
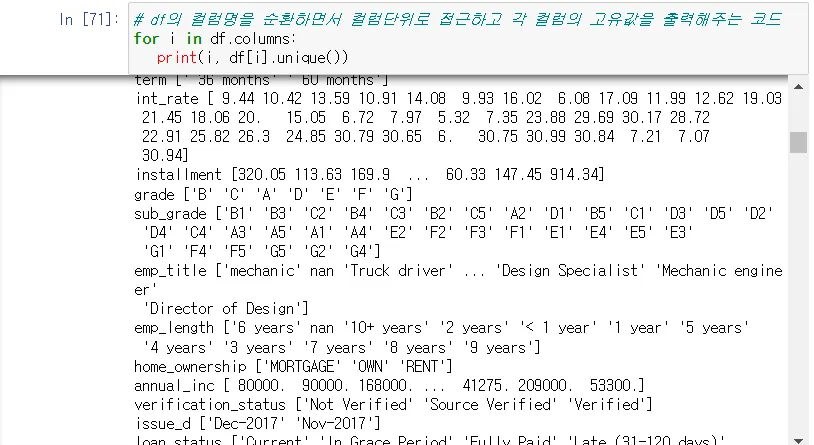

데이터 프레임의 구조
•
딕셔너리 → 내부는 array로 묶여져 있음

•
df[df['grade'] == 'A']['emp_title'] 신용등급이 A인 샘플의 emp_title 확인

•
df[df['grade'] == 'A']['emp_title'].unique() → 이 경우 고유 값이 어레이 형태로 나옴

•
df[’loan_amnt’].mean() 평균값
•
df[(df['grade'] == 'A') | (df['grade'] == 'B')] 그레이드가 A면서 B인 값
•
idmax
◦
argmax는 샘플링 전 전체 데이터 인덱스를 빼오기 때문에
◦
조건식으로 데이터를 선별 한 이후에는 idxmax, idxmin 함수를 사용
# df grade C 와 D 인 채권샘플 annual_inc 최대값인 인덱스 빼오기 (idxmax)
df[(df['grade'] == 'C')| (df['grade'] == 'D')]['annual_inc'].idxmax()
# 최대값 인덱스 빼와서 샘플까지 출력
df.take([df[(df['grade'] == 'C')| (df['grade'] == 'D')]['annual_inc'].idxmax()])
Python
복사
•
df[df['purpose'].str.contains('card')] 문자가 있는지 확인
‘Cannot mask with non-boolean array containing NA / NaN values’ 라는 오류가 발생하는 경우는 NAN값이 포함되어 있어서임 이럴때는 아래처럼 설정
df[df['emp_title'].str.contains('mechanic',na=False)]
6. 데이터프레임 병합
•
실제 분석업무를 진행하다보면 데이터가 여기저기 분산되어 있을 경우가 더 음
•
조각난 데이터를 분석에 필요한 데이터셋으로 만들기 위해 데이터프레임 병합을 사용.
6-1. 데이터 병합에 사용가능한 key(병합할 기준이 되는 행 or 열)값이 있는 경우
pd.merge(베이스데이터프레임, 병합할데이터프레임) → 조건을 주고 이어붙이는 것
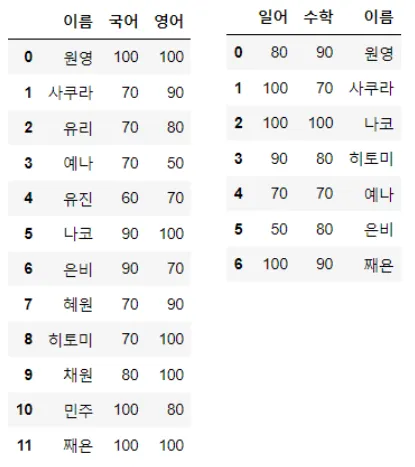
•
키 값이 같은 경우
pd.merge(merge_df1, merge_df2, how = 'outer')
◦
how : 'left', 'right', 'inner', 'outer'
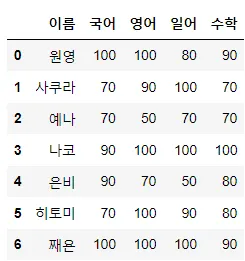
▪
left: 왼쪽 데이터프레임 기준으로
▪
right: 오른쪽 데이터프레임 기준으로
▪
inner: 양쪽 데이터 프레임에 데이터가 모두 있는 경우만
▪
outer: 한쪽에만 있어도 데이터를 합침
•
키 값이 다른 경우
◦
left_on : key값이 다를 경우 베이스데이터프레임의 key 설정/ right_on : key값이 다를 경우 병합데이터프레임의 key 설정
pd.merge(merge_df1, merge_df2, how = 'outer', left_on = '이름', right_on = 'name')
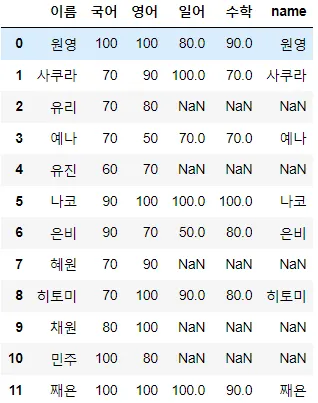
6-2. 단순 데이터 연결
pd.concat([베이스데이터프레임, 병합할데이터프레임], axis=0 or 1) → 그대로 이어붙이는 것
axis : 축 방향 설정
1.
이어붙일 데이터 두개의 컬럼 등이 같은지 검증하기
•
df.shape, df1.shape
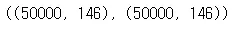
•
df.columns = df1.columns

2.
이어붙이기 pd.concat([df, df1])
•
pd.concat([df, df1], axis = 0) 아래로 이어붙이는것
shape → 100000, 146
•
df3 = pd.concat([df, df1], axis = 1) 옆으로 이어붙이는 것
shape → 5000, 292
7. 인덱스 편집
•
concat_df.reset_index() 인덱스를 다시 리셋(기존 인덱스도 존재)
◦
reset_index(drop = True) 기존인덱스를 버림
◦
reset_index(drop = True, inplace = True) 원본값은 버리고 저장하는 것
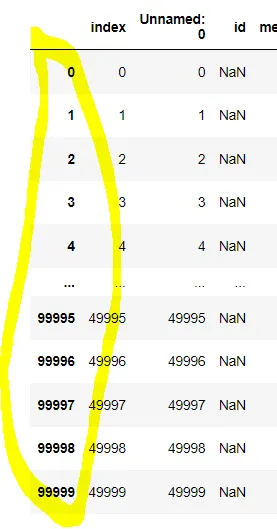
•
concat_df.set_index('loan_amnt') 인덱스를 다른걸로 다시 설정
8. 컬럼선택, 편집, 삭제
•
컬럼선택
◦
df.columns
컬럼안에서 선택은 df.columns[0]
•
컬럼삭제
1.
df.info()로 null 값이 있는지 확인
2.
person_df['id'].isna().all()로 null 값이 있는지 확인. 전체가 null 이면 ‘True’가 나옴
3.
del person_df[’member_id’]
또는 person.df.drop(’member_id’, axis = 1)
또는 person_df.pop(’member_id’)
•
컬럼명 변경
person_df.rename(columns = {'home_ownership':'home'})
9. 데이터 샘플링 분석
1.
데이터 값 확인
•
값을 카운트 하기 df['emp_title'].value_counts()
•
슬라이싱도 가능 df['emp_title'].value_counts()[:20]
근데 문제가 있음! → Manager와 manager 소문자 대문자로 구분되어있는 경우가 있음
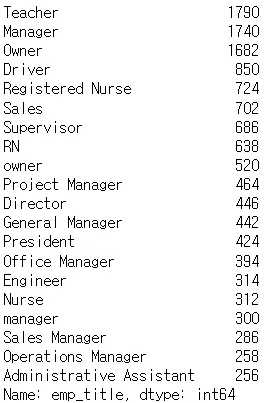
2.
astype(str) 소문자 변환 전 혹시모를 int, float 데이터가 있을지 모를 상황에 대비해서 모두 문자열로 변경
3.
모든걸 다 소문자로 바꾸기 전에 index 넘버를 다 삽입해주는 작업

d.
다 소문자로 바꾸기 권장하지 않음 너무 오래걸림!
for index, item in enumerate(df['emp_title']:
df.loc[index, 'emp_title'] = item.lower()
Python
복사
5.
다른 방법으로 다 소문자로 바꾸기
•
numpy를 학습하면서 브로드캐스팅에 관하여 잠깐 언급했었습니다. 그렇다면 그 파워풀하다던 브로드캐스팅은 어떻게 사용해야할까요?
•
apply 함수로 컬럼에 적용시키는 코드 구조
◦
df['컬럼명'] = df['컬럼명'].apply(lambda x: func(x) if 조건문)
◦
df['컬럼명'] = df['컬럼 kt명'].apply(func_nm)
•
대문자 만드는 함수
#함수만들기 -------------
def upper_function(x):
return x.upper()
#컬럼에 적용하기---------
df['emp_title'].apply(upper_function)
Python
복사
10. 데이터 재구조화
groupby 하는 기능, 엑셀의 pivot table과 비슷한 기능
•
df.groupby(’emp_title’).mean()
emp_title기준으로 데이터를 같은 기준끼리 묶고 그들의 평균을 내
◦
unique값이 나옴(아래의 경우 20912개)
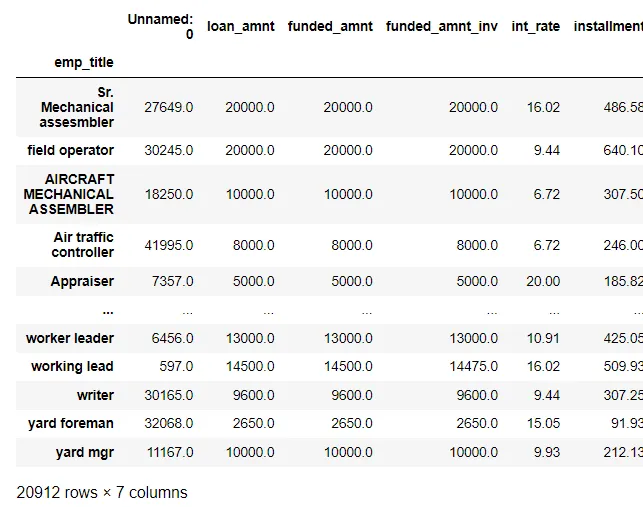
•
df.pivot_table 엑셀의 피벗테이블과 유사
# pivot_table-----------------------
pd.pivot_table(df, #전달할 데이터 프레임
columns = , #기준1
index = , #기준2
values , #정리되는 데이터
aggfunc = #어떤기준으로 정리할꺼냐)
# 신용등급과 거주구분에 따른 이자율 평균을 데이터프레임으로 다시 만든 것
pd.pivot_table(df,
columns = 'grade',
index = 'home',
values = 'int_rate',
aggfunc = np.mean)
Python
복사
11. 결측치 처리
•
df[’emp_title’].isnull() null이 몇개 인지 값 확인
◦
데이터 결측치율이 적은 경우 평균으로 대체하는 경우가 많음
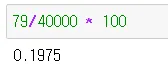
•
df[df['dti'].isnull()].index 결측치가 있는 인덱스 확인
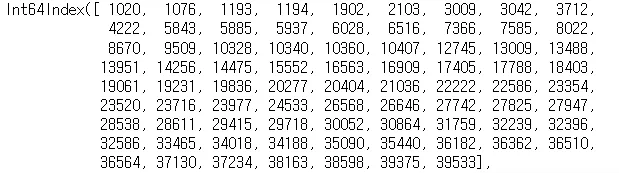
•
df[’dti’].fillna(df['dti'].mean()) NaN 값을 평균으로 채우기
•
앞뒤에 있는 데이터로 결측치를 채우는 방법
df['dti'].fillna(method = 'bfill')
df['dti'].fillna(method = 'ffill')
→ df['dti'].fillna(method = 'bfill').fillna(method = 'ffill')
•
df.dropna() 문자 결측치 제거