Matplotlib
1. Matplotlib
•
import matplotlib.pyplot as plt 설치 및 불러오기

1-2. 기본적인 line plot 그리기
line plot은 시간 혹은 순서에 따라 데이터가 어떻게 변화하는지를 보기위해 주로 사용 (ex) 주가데이터, 전력수요량, 매출, 수요)
•
그래프 모양 잡기

◦
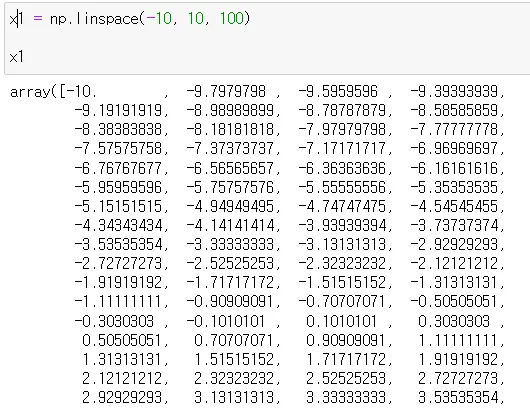
다른 방법 x1. np.linespace()
→ -10부터 10까지 100개를 만들어줌
•
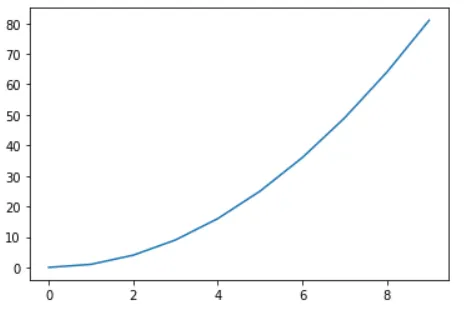
plt.plot(x,y) 라인 그래프 만들기
◦
x = np.arange(10), y = x^2
◦
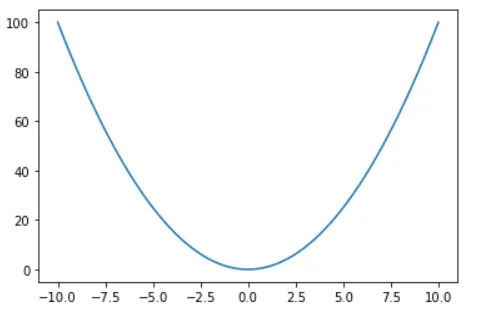
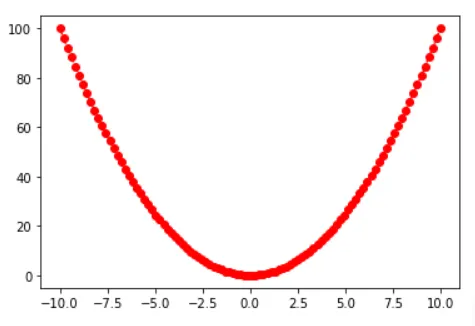
x1 = np.linspace(-10, 10, 100), y1 = x1^2
1-3. 스타일 지정하기
•
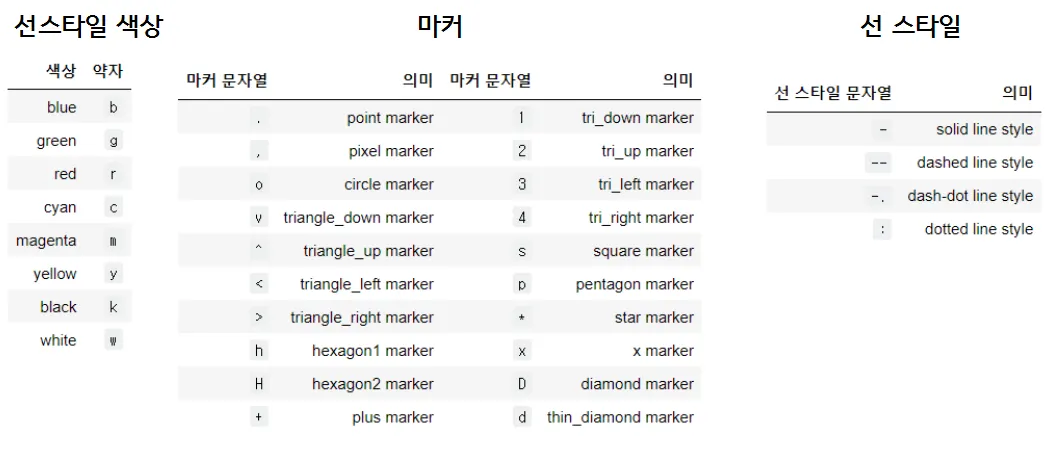
스타일 정리
•
plt.plot(x1, y1, 'ro:') 색상, 마커, 선 스타일 순서대로 적용
1-4. 그래프 옵션 추가하기
•
그래프 옵션 리스트
◦
figure : 그래프가 그려지는 캔버스 설정
◦
title : 그래프 제목
◦
xlabel, ylabel : 축 설명
◦
legend : 범례이름
◦
xlim, ylim : 축 범위
◦
xticks, yticks : 축 구간 내 필요한 구간만 추리기
•
두개의 그래프
◦
plt.legend()위에 두 식에서 label로 정해준 것이 네모칸 안에 나옴
◦
x.lim/y.lim x, y축의 범위를 설정해줌

1-5. Subplot
•
한번에 두 개 그리기
◦
plt.subplot(2,1,1) → 2행 1열의 첫번째 그래프로 그리겠다

1-5. bar plot
범주형 데이터(구간이 나누어져 있는) 데이터의 갯수, 빈도를 나타내는 데 쓰임
•
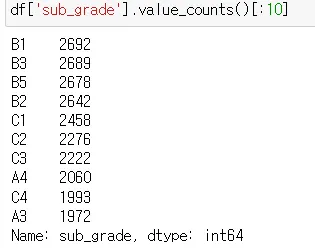
데이터를 기반으로 bar plot 나눌 준비
◦
x축 df['sub_grade'].value_counts().sort_index(ascending = True)
→ 알파벳기준으로 정렬

◦
y축 df['sub_grade'].value_counts().values

•
bar plot 만들기
plt.figure(figsize = (20,10)) 20 → 가로, 10 → 세로
plt.bar(df['sub_grade'].value_counts().sort_index().index, df['sub_grade'].value_counts().values)
→ sort_index() 인덱스 기준으로 정렬
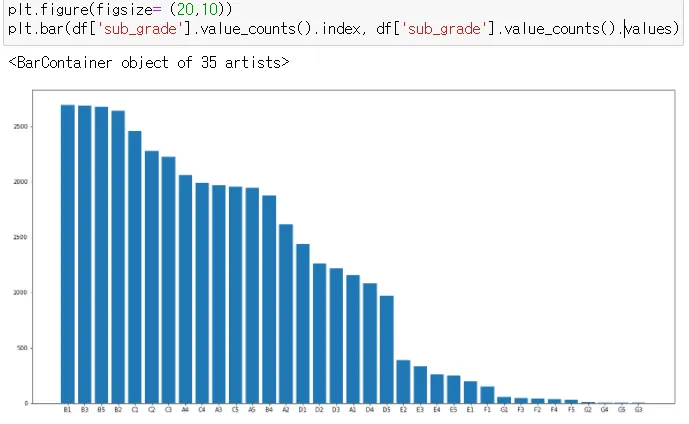
•
barh plot 만들기
plt.figure(figsize= (20,10))
plt.barh(df['sub_grade'].value_counts().sort_index(ascending = False).index, df['sub_grade'].value_counts().values)
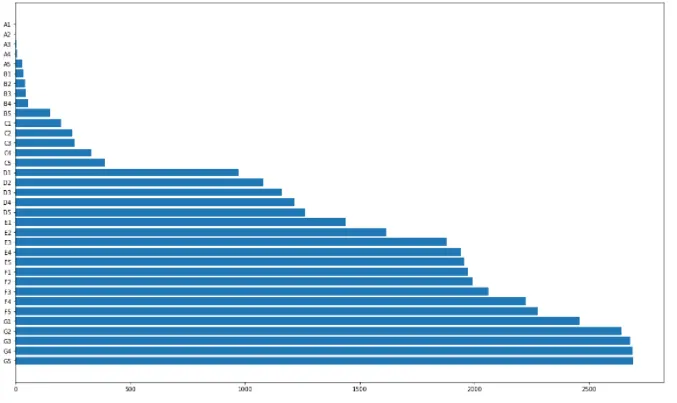
1-6. Histogram
데이터의 분포를 확인할 수 있는 시각화 방법
•
histogram 그리기
plt.hist(df[’loan_amnt’], bins = 30) bins는 막대를 더 늘려줌
plt.show() 상단에 이상한 array들을 없애줌
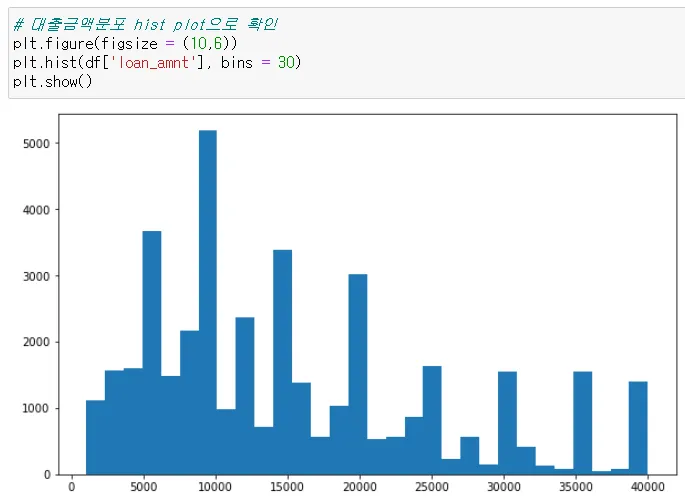
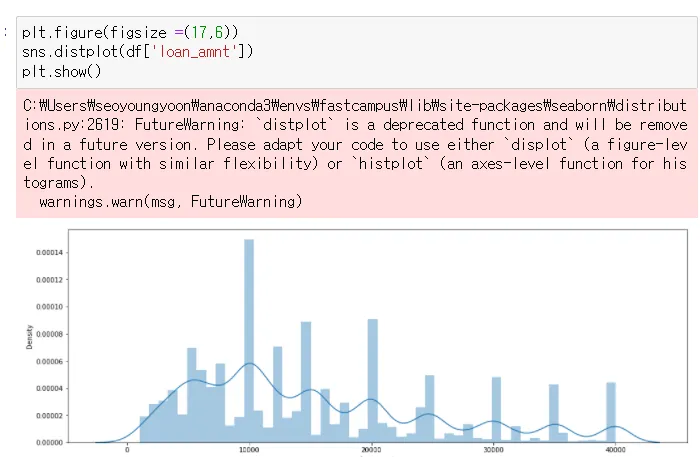
→ 5000으로 떨어지는건, 사람들이 5000단위로 딱 떨어지게 빌리는 경우가 많다는 것을 알수있음
1-7. Scatter Plot
X축과 Y축에 각각의 변수 데이터를 위치시키고 포인트들이 자리한 평면상의 분포를 통해 상관관계를 파악 가능
•
scatte 그리기
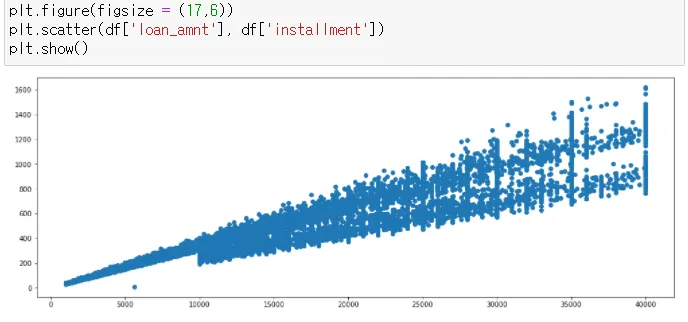
→ 양의 상관관계를 보임
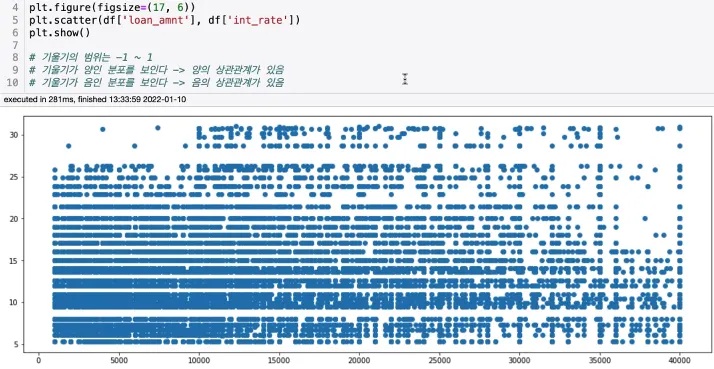
→ loan_amnt와 int_rate는 크게 관련이 없어보임
Seaborn

matplotlib에 비해 기본적인 시각적 심미성이 뛰어남
1. barplot
•
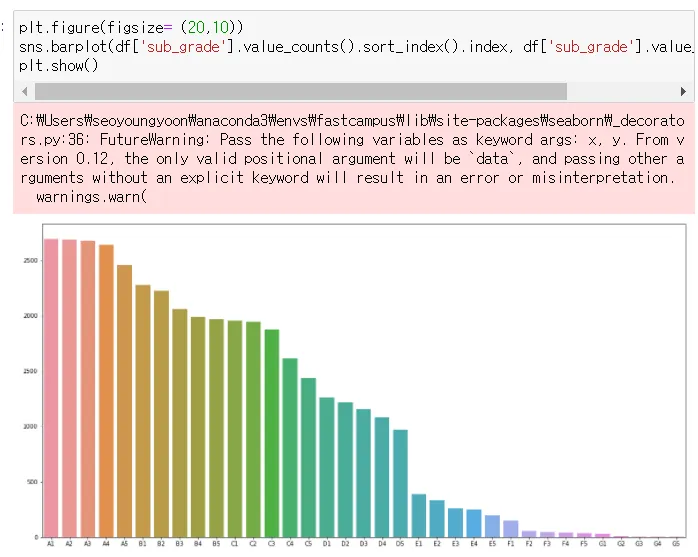
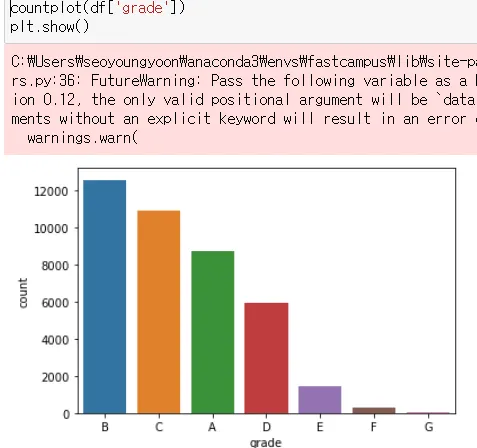
2. Countplot
•
간단한 barpot
3. Displot(히스토그램)
•
sns.distplot(df[’loan_amnt’])
4. Scatterplot
•
scatterplot
→ 상관관계가 별로 없어 보임
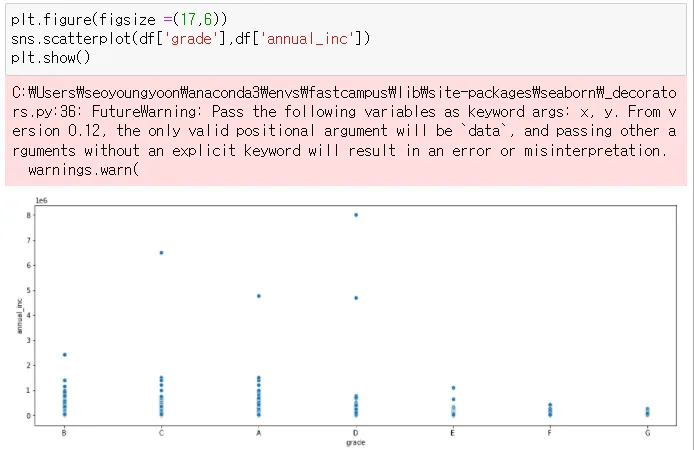
•
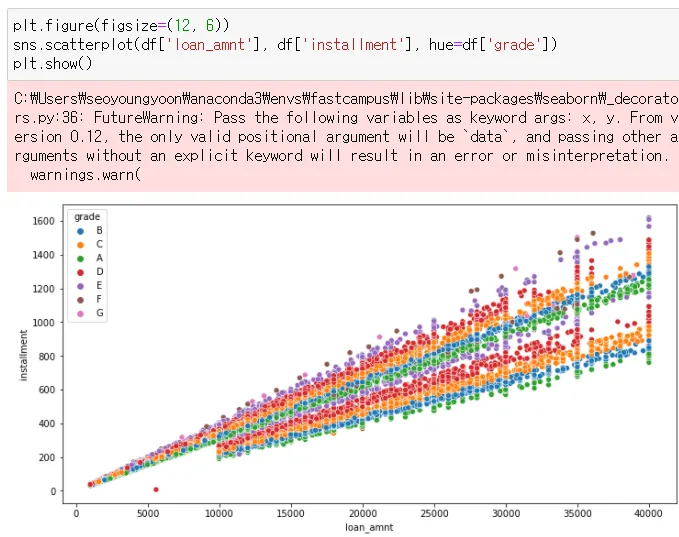
scatterplot, hue
hue → 왼쪽 grade박스와, 컬러가 생김
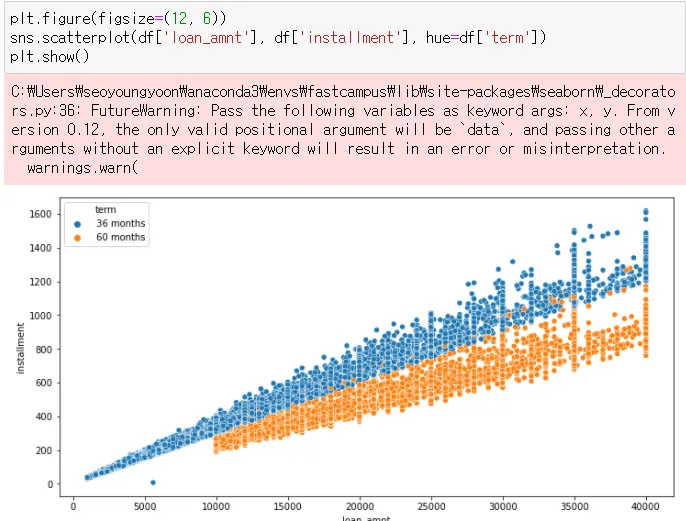
→ term이 짧을수록 installment도 적은 특성을 보임
5. Boxplot
scatterplot과 같이 두개의 변수를 분석하는 방법으로 사용 → 변수 2개 전달
구간의 차이를 분명하게 보여줌
각각의 box 하나당 해당 데이터의 사분위수, 중앙값, 최대, 최소값을 표기함
•
boxplot

→ 등급별로 이자율이 겹치는 부분이 없음
→ 등급이 높아질수록 대체로 이자율이 높음
→ A~F까지는 이율 범위가 있는데 G등급은 이율이 고정적으로 정해져있음
(이자율에 상환이 있는 것)
→ 점으로 된 건 이상한 애들임.. 이상치!
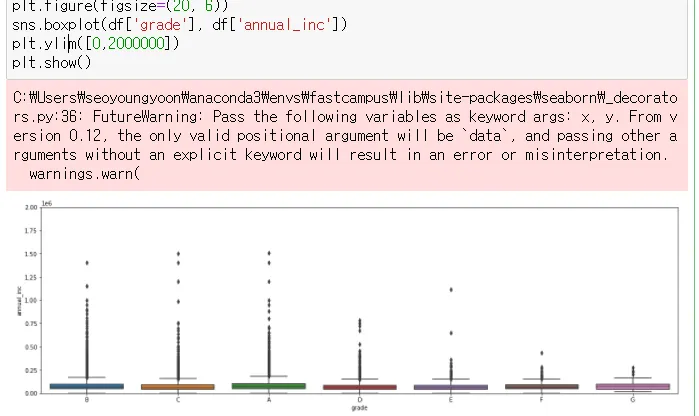
plt.ylim([0,22000]): 조건을 걸어서 범위를 늘려줌
→ 등급에 따라 연봉이 상관관계가 있지는 않아보임
→ 다만, 일반적인 분포 외에 고속득을 올리는 사람들이 A등급이 훨씬 많음
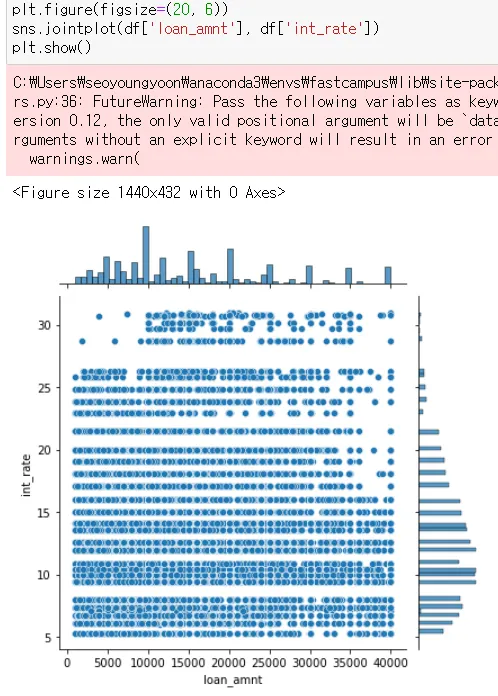
6. Jointplot
loan_amnt, int_rate의 scatter plot + hist plot의 결합형태인
•
jointplot
→ int_rate, loan_amnt에 대한 분포도와 scatter plot을 한번에 볼 수 있음
◦
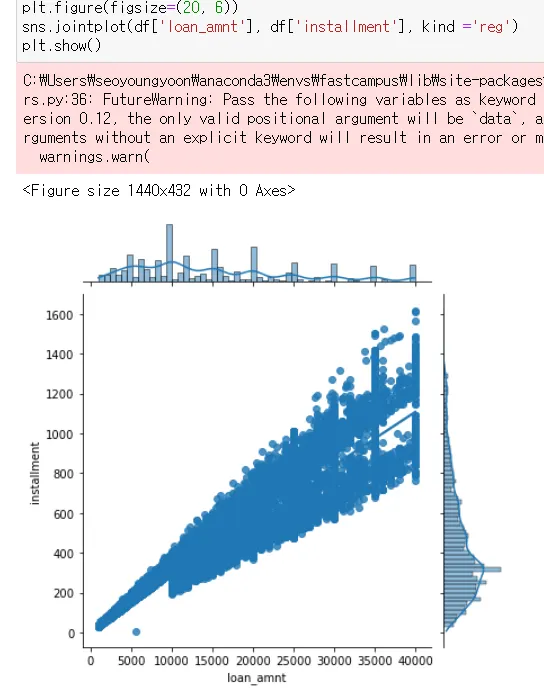
kind = ‘reg’ 일 경우
◦
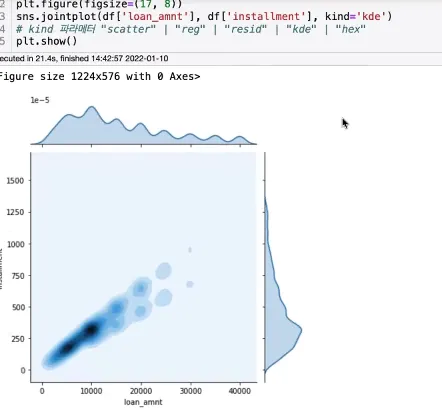
kind = ‘ked’일 경우
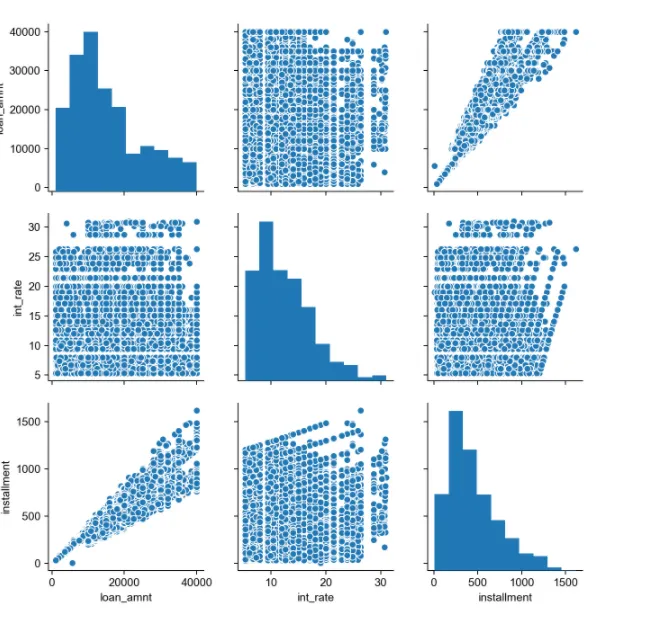
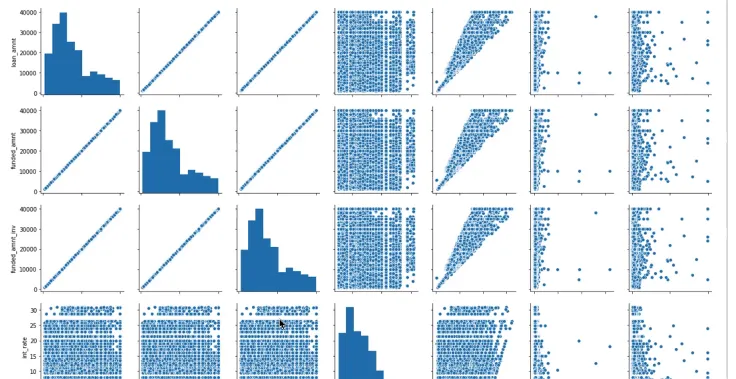
7. Pairplot
각 컬럼간 모든 scatter plot을 그리는 pairplot(다 그려줌)
숫자형태로만 만들어줌
•
pairplot

8. Heatmap
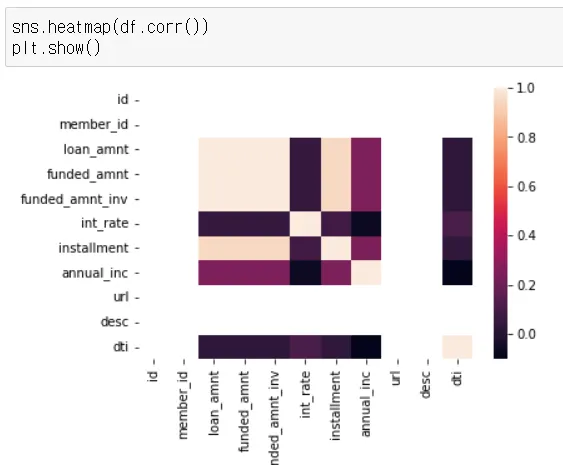
•
df.corr 상관관계를 알려줌
•
heatmap
→ 옅을수록 상관관계가 높다
9. 기타 추천

옆으로 움직일때마다 그래프를 움직이는 등


전문적으로 시각화하는 사람들이 만들어 놨음(유료인듯)