간단한 데이터 크롤링으로 기본 개념잡기
•
크롤링이란?: 크롤러(crawler)는 자동화된 방법으로 웹을 탐색하는 컴퓨터 프로그램
1.
정보를 가져오고자 하는 url 정의
2.
url 정보로 requests로 정보 요청
3.
text 정보를 html로 변환
4.
html에서 우리가 필요한 정보만 선별
1. 네이버 메인페이지 크롤링
1.
크롤링 준비
# url정의----------------------
url = 'http://naver.com'
# requsts로 url에 정보요청 ----
로컬 컴퓨터에서 네이버에 내가 네이버페이지로 이동할거니까 정보 내려라는 뜻
resp = requests.get(url)
# 정보를 html 변환 (보기 쉽게)
이거 html이니까 그걸로 바꿔라
html = BeautifulSoul(resp.text, 'html.parser')
# html 내에서 우리가 보고 싶은 정보만 선별
Python
복사
2.
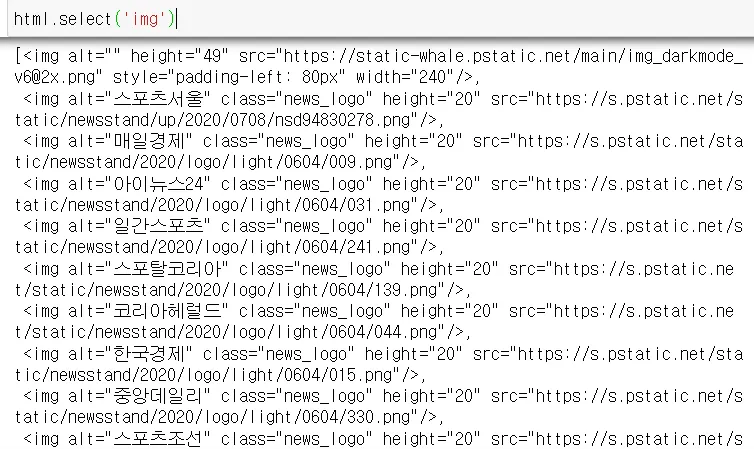
확인 resp.text
html html로 바꾼 자료
html.select(’img’) 이미지만 확인
2. 다음 페이지 크롤링
•
전체페이지 크롤링
1. requsts로 url에 정보요청
daum = requests.get('https://www.daum.net')
2, 정보를 html 변환 (보기 쉽게)
html_daum = BeautifulSoup(daum.text, 'html.parser')
Python
복사
•
로또번호
lotto = requests.get('https://search.daum.net/search?w=tot&DA=YZR&t__nil_searchbox=btn&sug=&sugo=&sq=&o=&q=%EB%A1%9C%EB%98%90')
daum_lotto = BeautifulSoup(lotto.text, 'html.parser')
for i in daum_lotto.select('span.ball'):
print(i.text)
Python
복사
•
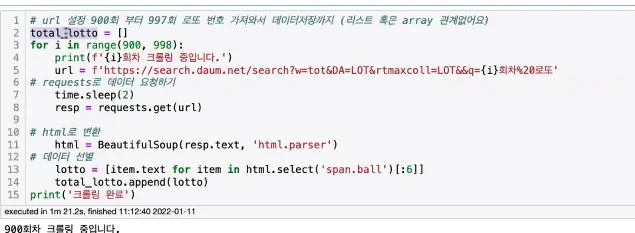
전체 로또 번호 → 잘 안됐음
import time → time.sleep(3) 코드를 3초마다 하게함
total_lotto = []
number = [997, 996, 995, 994]
for p in number:
print(f'{p}회사 크롤링 중입니다.')
url = f'https://search.daum.net/search?w=tot&DA=LOT&rtmaxcoll=LOT&&q={number}%ED%9A%8C%EC%B0%A8%20%EB%A1%9C%EB%98%90'
time.sleep(3)
resp = requests.get(url)
html = BeautifulSoup(resp.text, 'html.parser')
lotto = [item.text for item in html.select('span.ball')]
total_lotto.append(lotto)
total_lotto
Python
복사
3. 슬의생 크롤링
•
코드는 두 가지로 확인 가능
(1) 보기 → 개발자도구에서 보기
(2) 해당 부분을 드래그해서 → 검사 클릭
•
드라마소개 크롤링
# 슬의생 드라마소개 크롤링
seul = requests.get('https://search.naver.com/search.naver?where=nexearch&sm=top_hty&fbm=0&ie=utf8&query=%EC%8A%AC%EA%B8%B0%EB%A1%9C%EC%9A%B4+%EC%9D%98%EC%82%AC%EC%83%9D%ED%99%9C')
# 정보를 html 변환 (보기 쉽게)
seul_html = BeautifulSoup(seul.text, 'html.parser')
# html 내에서 우리가 보고 싶은 정보만 선별
seul_html.select('span.desc')[0]
Python
복사

→ 리스트로 구성되기 때문에 [0] 인덱싱해서 갖고옴

→ 아래처럼 만들어두면 키워드만 넣으면 그냥 긁어올수있음
keyword = input('드라마 제목을 입력하세요:')
seul = requests.get(f'https://search.naver.com/search.naver?where=nexearch&sm=top_hty&fbm=0&ie=utf8&query={keyword}')
# requsts로 url에 정보요청
# 정보를 html 변환 (보기 쉽게)
seul_html = BeautifulSoup(seul.text, 'html.parser')
# html 내에서 우리가 보고 싶은 정보만 선별
seul_html.select('span.desc')[0].text
Python
복사

•
슬의생 관련 블로그 글 크롤링

4. HTML 기본 구성
•
웹 페이지의 구성
◦
HTML(Hyper Text Markup Language)
www 를 구성하는데 사용하는 국제표준 언어로서 컨텐츠와 레이아웃을 담고 있다
◦
<태그> 내용 </태그>
<tag이름 class="class이름1 class이름2" id="주민번호" href="주소"></tag이름>
◦
형태나 속성을 묘사하기 위한 구조적 언어
HTML, CSS (계층이 있음)웹의 작동 및 제어를 위한 프로그래밍 언어 : Js
•
셀렉터
◦
기본
> 용도 : html에서 내가 원하는 내용을 찾아내기 위해서
<span class="news" id="1234">비비고 왕교자</span>
>> 단일 셀렉터
html.select('span') # 태그 이름이 span인 친구들을 다 들고옴
tag : span
class(별명, 그룹명) : .news
>> 클래스 포함 셀렉터
html.select('span.news')
>> id 포함 셀렉터
id(고유값) : #1234
html.select('span#1234')
Python
복사
◦
복합셀렉터
1. 조합 셀렉터
<span>1</span>
<span class="txt">2</span>
<em class="txt">3</em>
태그 이름이 span이고 클래스 이름은 txt인 라인을 찾고 싶다. : span.txt
li 태그 중에서 id가 name 인 라인을 찾고\ 싶다. : li#name
2. 경로 셀렉터
<ul>
<li><span>이걸 찾으려면?</span></li>
</ul>
<span>이건 아님</span>
ul 태그안 li 태그 안 span 라인을 찾는다
ul > li > span 혹은 ul li span
Python
복사
5. 원하는 주식 갖고 오기
# url 정의
url = 'https://finance.naver.com/item/main.nhn?code=005930'
# requests 요청
resp = requests.get(url)
# html 변환
html = BeautifulSoup(resp.text, 'html.parser')
# 시가총액, 외국인 소진률, PER, PBR
html.select('em#_market_sum')[0].text.strip()
JavaScript
복사
→ id를 가져올때는 앞에 #
→ strip은 뒤에 공백을 없애주는 공식