1. Standard SQL
•
관계형 데이터베이스에서 원하는 정보를 유도하기 위한 기본 연산 집합
비 관계형 데이터베이스는 No SQL이라고 함 (ex. mongo DB)
→ 일반 집합 연산
→ 순수 관계 연산
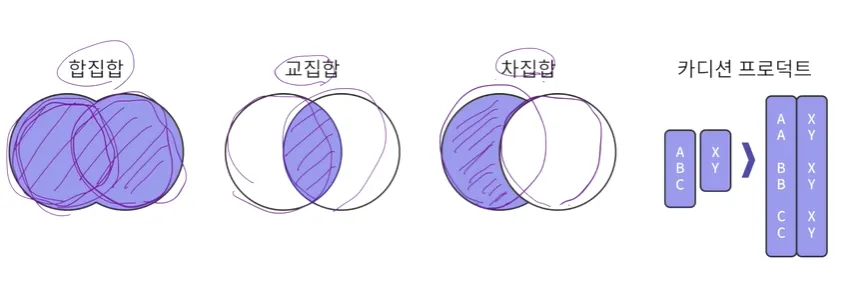
일반 집합 연산
•
카디션 프로덕트: 두개의 테이블이 있을때 해당 테이블의 데이터에 대해서 모든 경우의 수를 살펴보는 것
→ JOIN과 연관이 있음
•
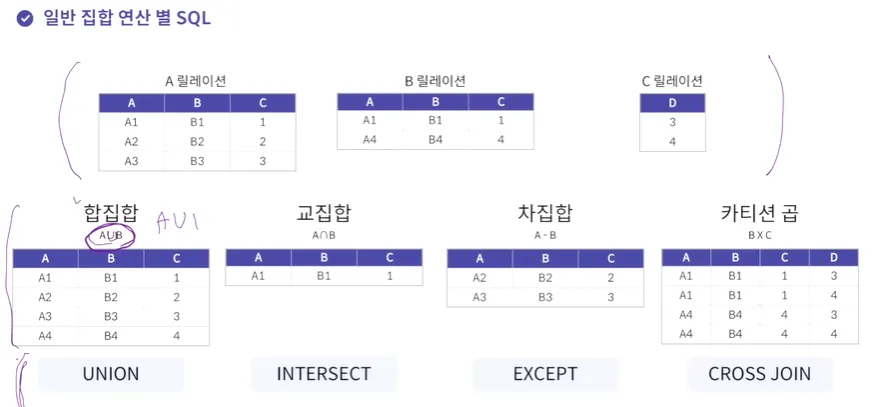
일반 집합 연산 SQL
◦
합집합 → UNION
◦
교집합 → INTERSECT
◦
차집합 → EXCEPT
◦
카티션 곱 → CROSS JOIN
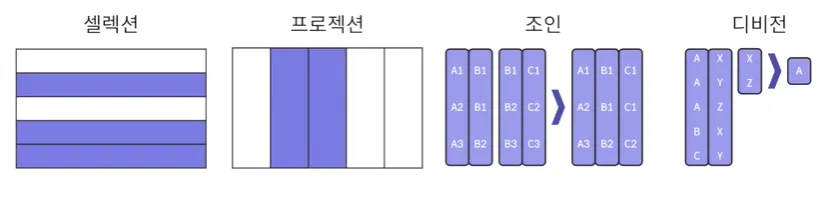
순수 관계 연산
•
셀렉션: 테이블이 있을 때 특정 행들만 조회하는 것
•
프로젝션: 테이블이 있을 때 특정 컬럼에 대해서 조회하는 것
•
조인: 두개의 데이터를 공통된것만 새로 출력하는 것
•
디비전: 두개의 테이블이 있을 때 연관된 데이터만 출력하는 것
→ X, Z 모두가 연관 있는 건 A이기 때문에 A가 출력 따로 사용하지는 않음
2. 집합 연산자 개념
집합 연산자
•
두 개 이상의 테이블에서 조인을 사용하지 않고 연관된 데이터를 조회하는 방법 중 하나
•
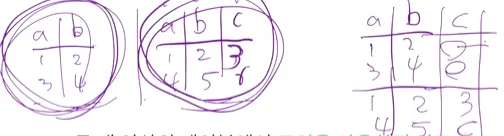
테이블에서 select한 컬럼의 수와 각 컬럼의 데이터 타입이 테이블 간 상호 호환이 가능해야 한다
◦
각 컬럼의 수와 각 컬럼의 데이터 타입 수가 일치해야 한다
◦
아래처럼 컬럼의 수와 데이터 수가 일치하지 않으면 오류남
•
키워드 정리
◦
합집합: UNION, UNION ALL
◦
교집합: INTERSECT
◦
차집합: EXCEPT
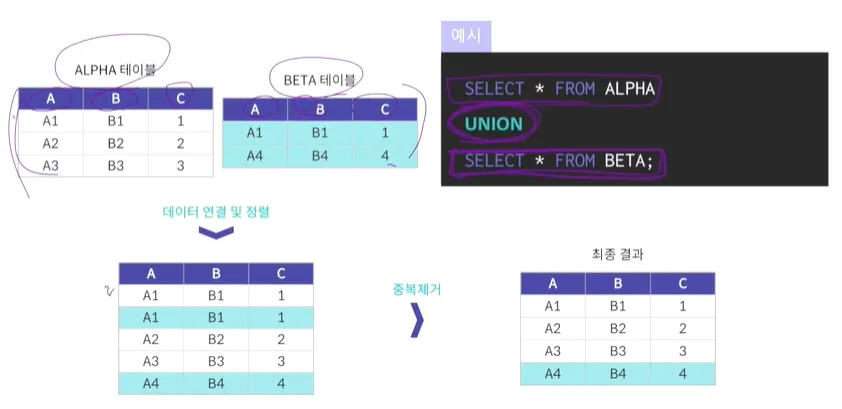
UNION
•
두 개의 테이블을 하나도 만드는 연산
•
UNION에 사용할 컬럼의 수와 데이터 형식이 일치해야 함
•
합친 후에 테이블에서 중복된 데이터는 제거
•
이를 위해 UNION 테이블을 합칠 때 정렬과정을 발생 시킴
(하지만 최종 결과에 대해 올바른 정렬을 하려면 order by 구문 사용 필요)
•
관계형 대수의 일반 집합 연산에서 합집합의 역할을 함
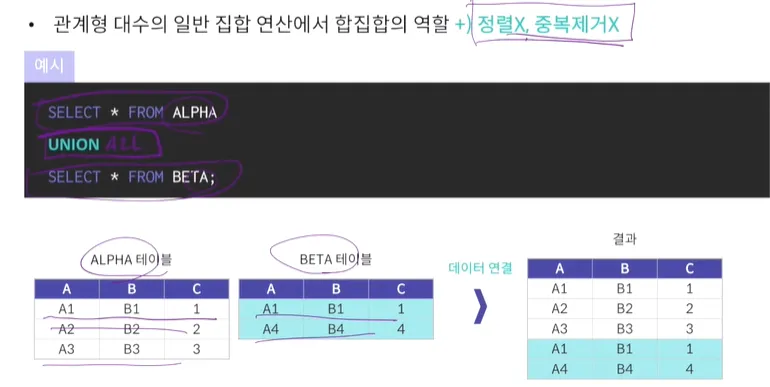
UNION ALL
•
UNION과 거의 같은 기능을 수행
•
다만, UNION과 달리 중복제거와 정렬을 하지 않음
중복제거를 하지 않는다는 것이 가장 큰 차이점
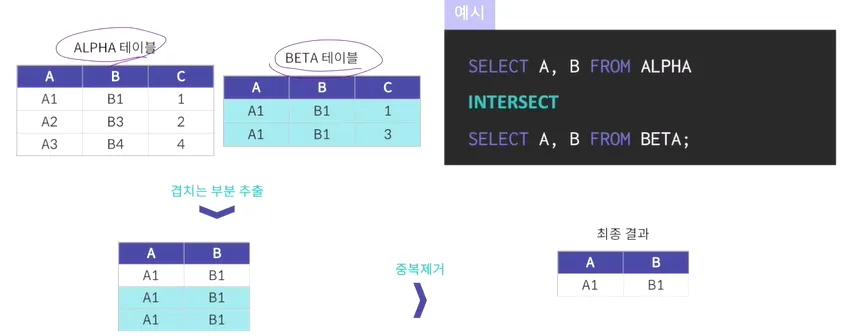
INTERSECT
MySQL에서는 지원되지 않음
•
두 개의 테이블에 대해 겹치는 부분을 추출하는 연산
•
추출후에는 중복된 결과를 제거
•
관계형 대수의 일반 집합 연산에서 교집합의 역할
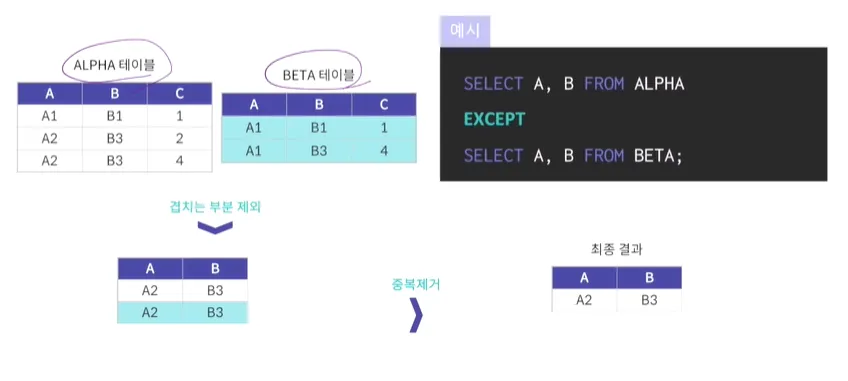
EXCEPT
MySQL에서는 지원되지 않음(키워드가 다름 minus로 사용중)
•
두 개의 테이블에서 겹치는 부분을 앞의 테이블에서 제외하여 추출
•
추출후에는 중복된 결과를 제거
•
관계형 대수의 일반 집합 연산에서 차집합역할
3. 계층형 질의
•
테이블에 계층열 데이터가 존재하는 경우 데이터를 조회하기 위해 사용하는 것
•
대표적인 데이터베이스 → ORACLE, SQL Server
계층형 데이터
•
동일 테이블에 계층적으로 상위와 하위 데이터가 포함되어 있는 데이터
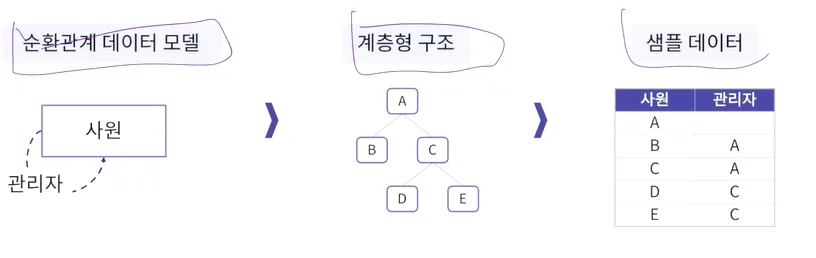
계층형 질의 예시(Oracle)
•
Start with : 최상위 data에 대해서 기준을 잡아 주는 것
•
Connect by prior : 상위 데이터와 하위 데이터를 어떻게 연결시켜줄 거냐

•
LPAD('', 4*(level-1)) || 사원번호 → b 갯수만큼 a 문자열을 왼쪽에 배치
→ 좀더 계층적으로 나타낼 수 있다
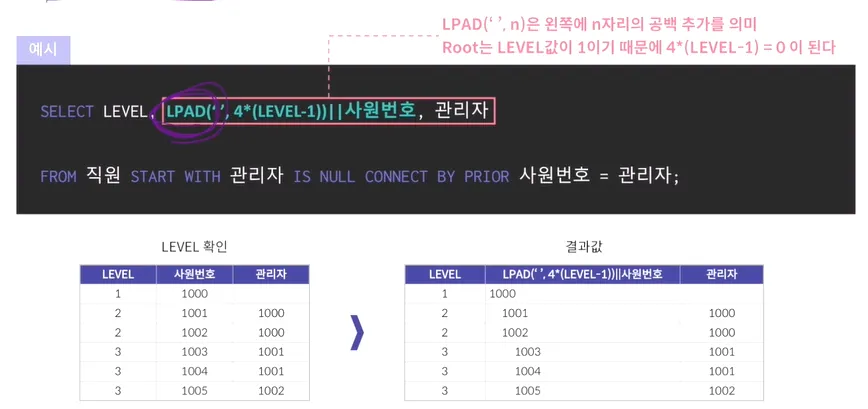
Connect by 키워드(Oracle)
•
LEVEL : 계층에서 최상위 레벨 1을 기준으로 아래 레벨 표시
•
Connect_by_root: 현재 데이터의 가장 최상위 데이터 값을 표시
•
Connect_by_isleaf: 현재 전개할 데이터가 최사위 데이터인지 0과 1로 표시
◦
0일경우: 최하위 데이터 아님
◦
1일경우: 최하위 데이터 맞음
•
Sys_connect_by_path(a,b): 최상위 데이터부터 현재까지 경로 표시
◦
예) sys_connect_by_path(사원번호, ':')


계층형 질의 예시(SQL Server)

계층형 질의 예시(MySQL/MariaDB)

•
WITH RECURSIVE CTE (칼럼, 칼럼, 칼럼) → 호출하고자 하는 칼럼명이 옴
→ 결과 테이블에 나오는 칼럼명들
•
AS → 뒤에 있는 쿼리를 계속해서 재귀호출해서 CTE 테이블을 만드는 것
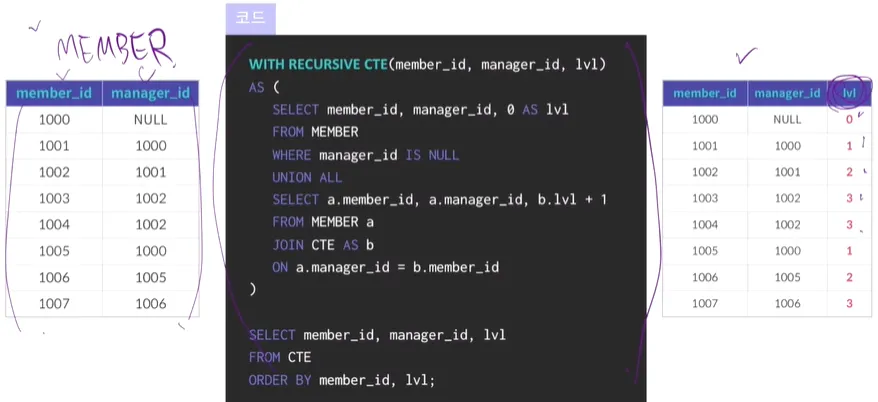
•
오라클에서는 start with 이었던 것을 maria db에서는 'where'로 표현
→ 1번째 순환, 최상위 값이 추출됨
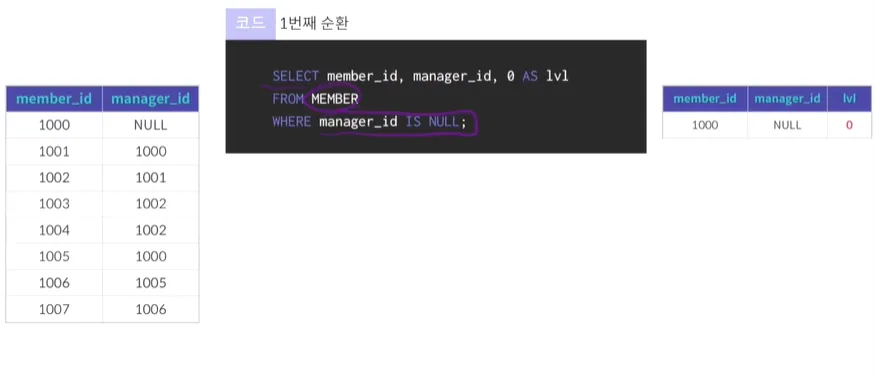
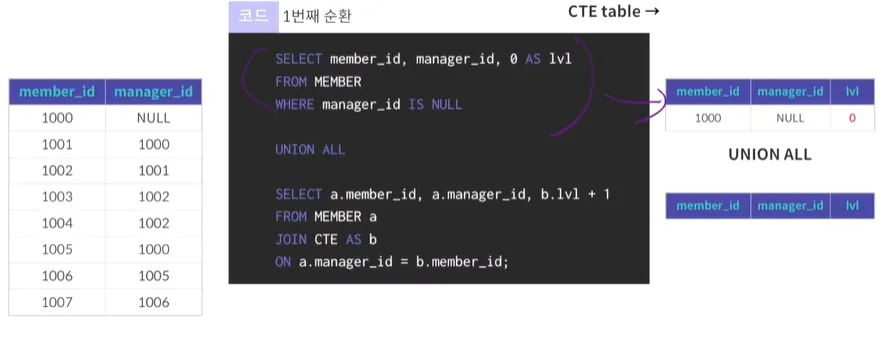

실무에서 응용해서 사용하기 보다는 거의 비슷하게 사용됨