CHAPTER 3-5. Data Type (List)
1. 리스트
•
자유롭게 수정이 가능함 (수정이 안되게 할때는 튜플을 사용)
•
리스트에는 다양한 타입의 원소를 포함할 수 있음

•
행렬처럼 표현할 수 있음

2. Indexing
•
리스트의 원소를 뒤에서 찾기
◦
L[-3]→ L[len(L) - 3] == L[5-3] == L[2]
•
원소를 가져다가 더할 수 있음
◦
리스트 L

◦
인뎅식해서 더하기

•
리스트 안의 리스트
◦
L2[1][0]→ 두번째에 있는 첫번째 숫자를 가져오기
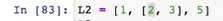
•
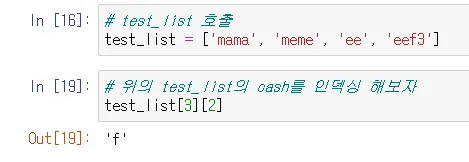
리스트 안의 문자
◦
4번째 인덱스 ‘eef’에서 3번째 인덱스 값을 가져옴
3. Slicing
•
전체 리스트의 일부를 자르는 것
•
예제
◦
L = [1,2,3,4,5] 일때
▪
L[ : -1] → L[ : len(L) - 1] = L [ : 5- 1 ] : L [ : 4]
▪
L[ -2 :] → L [ -2 : len(L)] = L[3 : len(L)]
4. 리스트 관련 함수
→ 리스트 활용
CHAPTER 3-6. Tuple, Set
1. 튜플
•
리스트와 거의 비슷하다
◦
indexing, slicing 모두 동일하게 사용 가능
◦
원소들도 자유롭게 사용 가능
•
다른점이 딱 2가지 있다
◦
튜플은 ( ) 라고 씀
◦
리스트는 생성후에 변경이 가능하고(mutable)
(e.g list, dict, set)
◦
튜플은 한번 생성이 되면 수정이 불가능하다(immutable)
(e.g int, float, string, tuple, frozenset)
→ 데이터를 수정했는지 모름, 데이터를 보호할 수 있음
2. 집합(Set)
•
집합에는 순서가 없다
→ indexing과 slicing을 쓸 수 없다
•
교집합, 차집합, 합집압을 모두 지원

◦
교집합: 집합1.intersection(집합2)

◦
합집합: 집합1 | 집합 2
(s1 + s2로 혼동 할 수 있는데, 이렇게 하면 값이 안나옴)

◦
차집합: 집합1 - 집합2

•
집합의 원소의 uniqueness를 활용 → 중복된 숫자들을 지워줄 수 있음
◦
리스트를 집합으로 바꿔줌

•
집합 관련 함수
◦
add → 집합에 원소 추가

◦
update → 여러 원소 추가하기
▪
s.updae하면 s에다가 업데이트를 하는 것
▪
s.union({4,5})는 4,5가 추가 된 새로운 집합을 보여주는 것
→ 출력 결과는 같지만 의미는 다르다

◦
remove → 원소제거

CHAPTER 3-7. Dictionary
1. Dictionary?
•
key - value 방법을 통해 저장함
•
key를 통해서 value에 access함
•
사전을 만들 때 key는 중복이 있으면 절대 안됨
→ 사전에서 key가 될 수 있는 data type은 immutable이어야 함
→ 수정X,
2. Dictionary 특성

•
사전의 모든 value들 보기 → D.values()

•
사전의 모든 key, value 쌍 보기 → D.items( )

•
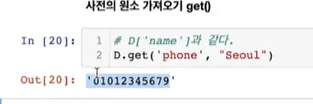
사전의 원소 가져오기 → D.get( )
◦
D[’name’]과 같은 값이 나옴
◦
그럼에도 쓰는 이유는, key값을 다 파악하고 있지 못하는 경우, 해당 key가 없으면 그때는 이 value값을 내놓아라 라고 설정 할 수 있음
오류를 피할 수 있음
▪
key값이 없는 경우: address가 key값으로 없기 때문에 seoul 출력

▪
key값이 있는 경우: seoul이라고 설정함에도 있는 value값이 나옴
•
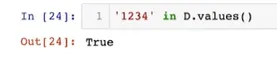
사전에 해당 key값이 존재하는지 확인하기 → in
◦
key 있을 때 / 없을 때

◦
value가 있는지 확인할 때
•
딕셔너리를 모두 다 삭제할 때 del my_wallet
•
딕셔너리의 모든 값들을 삭제 my_wallet.clear()
•
딕셔너리의 키만 확인 my_wallet.keys()
•
딕셔너리의 값만 확인 my_wallet.values()