1. 데이터 분석 개요

윈도우 함수
•
순위, 집계 등 행과 행 사이의 관계를 정의하는 함수
•
OVER구문을 필수 로 한다
•
SELECT위에 어떤 윈도우 쓸것인지, 그 이후에는 ‘OVER’절을 사용

◦
PARTITION BY
▪
예) EMPLOYEE의 테이블에 DEPARTMENT_ID가 있다고하고, 이 기준으로 소그룹을 나눈다고하면 DEPARTMENT_ID를 기준으로 소그룹을 나누어서 실행 됨

윈도우 함수 - 순위 함수
•
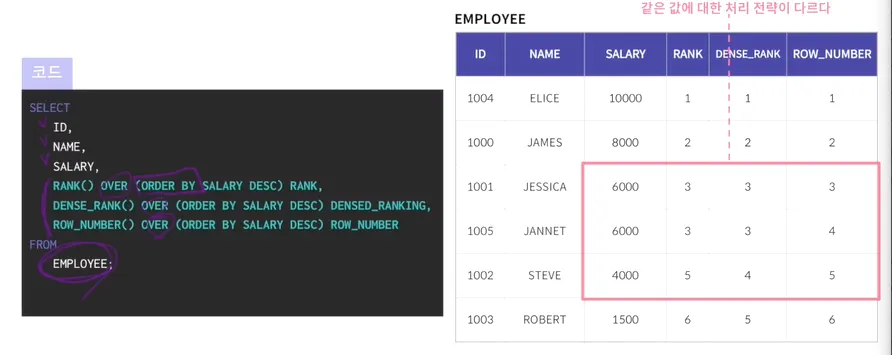
Rank: 동일한 값에는 동일한 순위를 부여하기 때문에 6000,6000에 대해서 3이라는
동일한 순위를 부여하였지만, 각각의 값을 다 건으로 인식하기 때문에
첫번째 3은 3번째, 두번째 3은 4번째로 인식해서 5번째는 5라고 나옴
•
DENSE_RANK: 같은 값에는 같은 순위를 부여하나, 같은 순위인 3을 묶어서 인식함
따라서 그 다음의 순위는 4라고 나옴
•
ROW_NUMBER: 값에 상관없이 순서대로 순위 부여

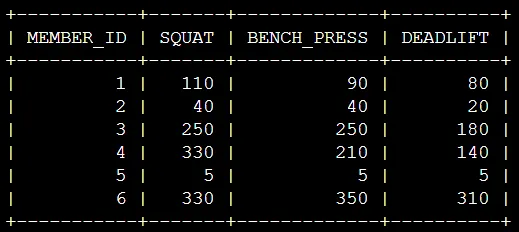
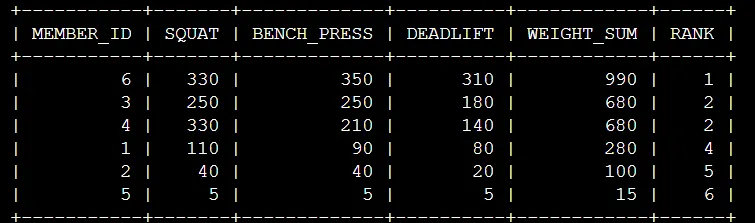
문제
전체 항목에 대한 SUM을 구해서 RANKING 매기기

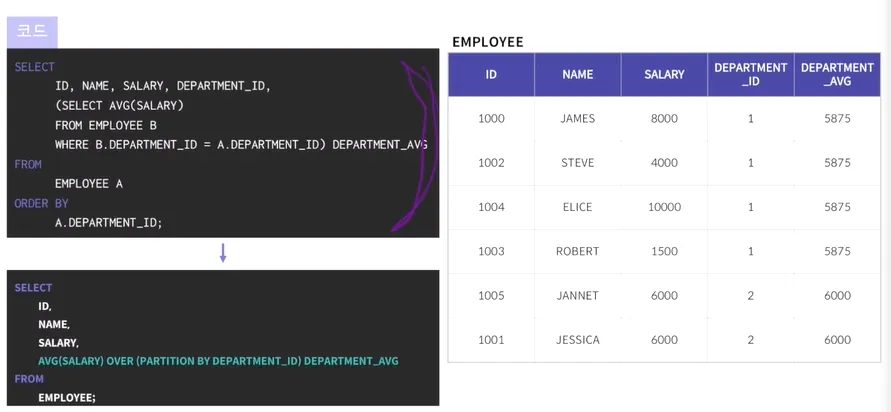
윈도우 함수 - 일반 집계 함수
•
일반 집계 함수(SUM, AVG,MAX,MIN...)를 GROUP BY 구문 없이 사용할 수 있다 .
•
아래는 기존에 DEPARTMENT별로 AVG를 구했던 것을 윈도우 함수로 사용한 것
→ AVG(SALARY) OVER(PARTITION BY소그룹으로 나누는 기준DEPARTMENT_ID) AS DEPARTMENT_AVG
→ DEPARTMENT_ID를 기준으로 AVG SALARY를 구하겠다
윈도우 함수 - 그룹 내 행 순서 함수
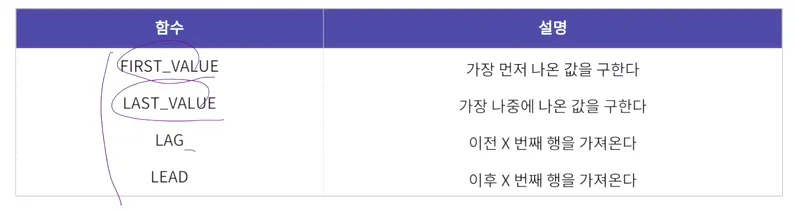
•
FIRST_VALUE, LAST_VALUE
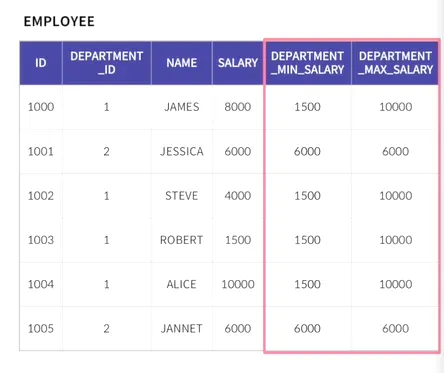
UNBOUNDED PRECEDING(윈도우의 첫번째 행)대신 CURRENT ROW(윈도우의 시작위치가 현재 행)가 들어갔다면?
윈도우의 시작지점이 자기 자신이기 때문에,
1003 → 1500, 1002 → 4000, 1000 → 8000 이라고 각각 나옴

◦
ARGUMENT → 추출하려고 하는 값
◦
BETWEEN A AND B: A와 B 사이에 있는 것을 다 포함하겠다
▪
ROWS: 행
▪
UNBOUNDED PRECEDING: 윈도우 첫번째 행
▪
UNBOUNDED FOLLOWING: 윈도우 마지막 행
•
아래의 데이테어스 윈도우 첫번째 행 1500에서 마지막 행 10000까지 살펴보겠다는 뜻


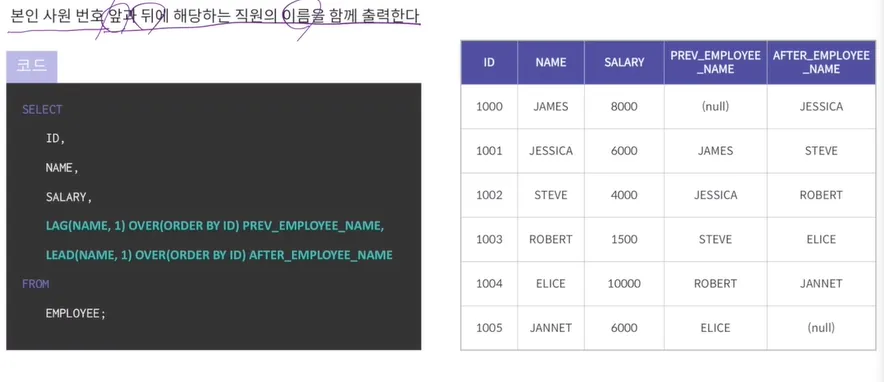
•
LAG, LEAD 함수
◦
LAG : 앞에 있는 데이터를 가져오는 것
◦
LEAD : 뒤에있는 데이터를 가져 오는 것
▪
예시) (NAME, 1) → NAME에서 데이터를 가져올 것이며 하나 뒤에있는 것을 가져올 것
윈도우 함수 - 그룹 내 비율 함수

•
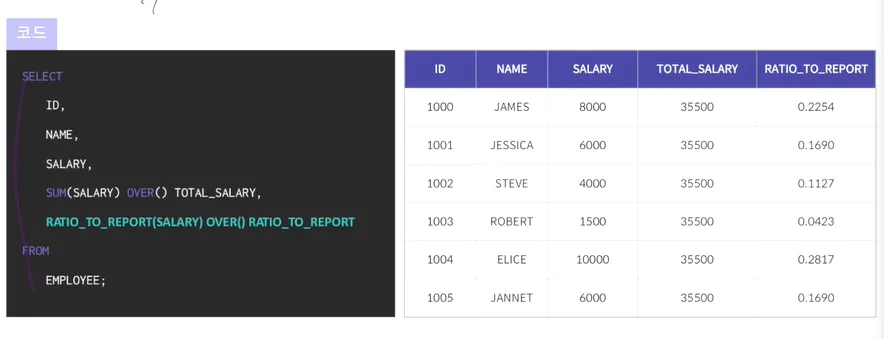
RATIO_TO_REPORT
직원 전체 급여의 합 중 각 행이 차지하는 비율을 출력+
•
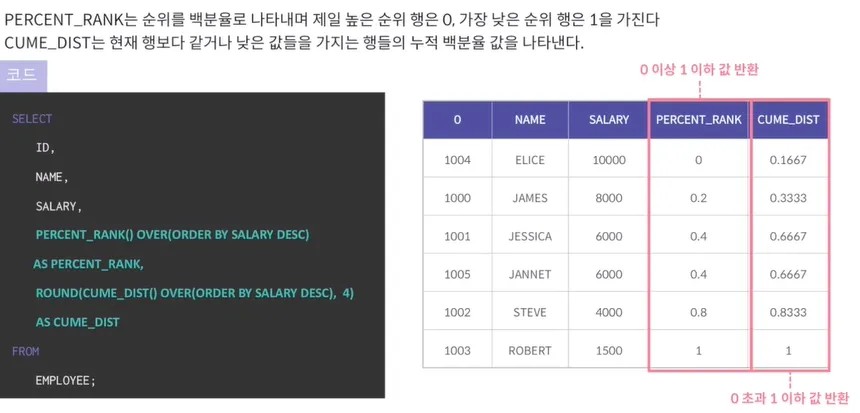
PERCENT_RANK, CUME_DIST
◦
ROUND함수
•
NTILE
◦
NTILE 3 → ORDER BY 기준으로 1,2,3으로 세개로 나눔
▪
딱 맞아떨어지지 않을때는 앞에 있는 그룹부터 하나씩 추가 됨

3. 그룹 함수

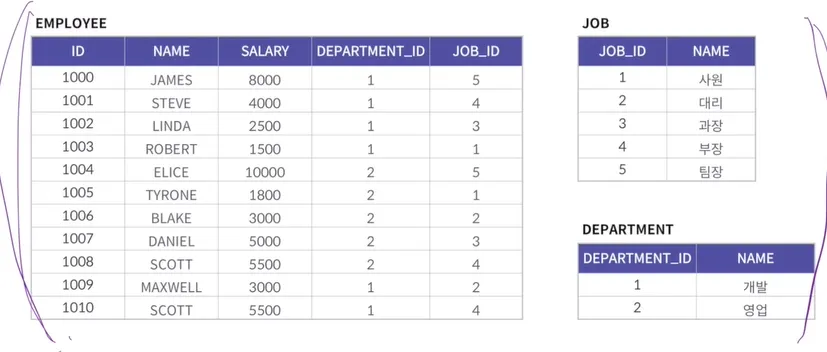
그룹함수 - 기반 테이블
•
GROUP BY
◦
GROUP BY로 쓸 수도 있고 PARTITION BY로 할 수도 있는데 실무에선 GROUP BY를 더 많이씀

•
ROLL UP
◦
그룹화하는 컬럼에 대한 부분적인 통계를 제공해준다
◦
가장 앞에 있는 것을 기준으로 ROLL UP 해줌
→ 아래의 경우에는 개발, 영업 등의 팀을 기준으로 ROLL UP 됨
◦
MARIA DB에서는:


•
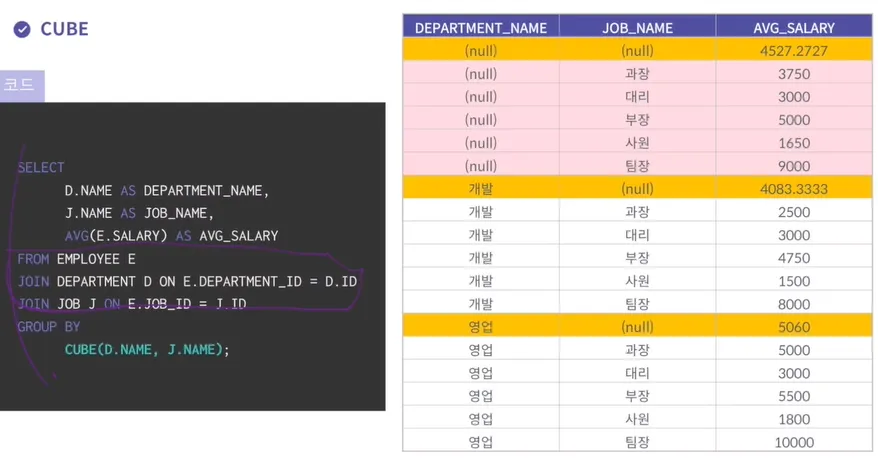
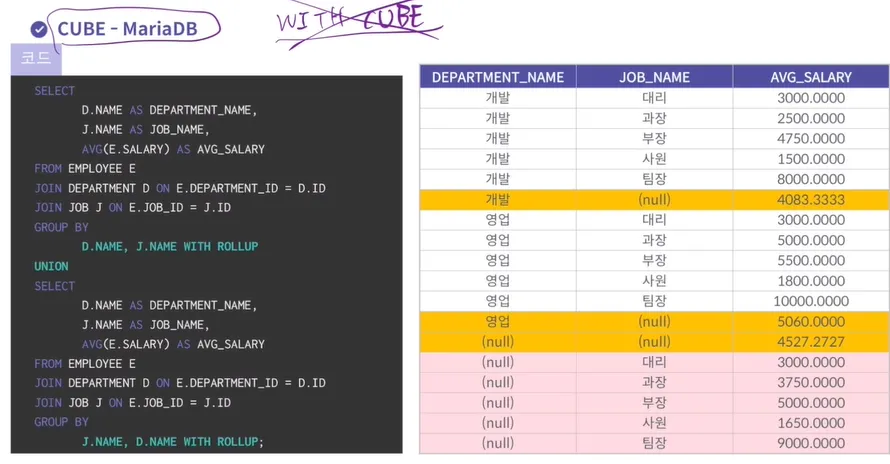
CUBE
◦
ROLLUP 함수에서 제공하는 결과를 포함해서, CUBE함수에서는 그룹화 하는 컬럼에 대한
결합 가능한 모든 경우의 수에 대해 다차원 집계를 생성한다
→ ROLL UP 함수들의 합

◦
MARIA DB 에서 사용할 때
그룹 함수 - GROUPING SETS
•
명시된 컬럼에 대해 개별 통계를 생성한다
•
각 칼럼에 대해 GROUP BY로 생성한 통계를 모두 UNION ALL한 결과와 동일
◦
예시) 아래 DEPARTMENT_NAME은 영업, 개발 JOB_NAME은 각 직급별로 개별적인 통계 가능

•
MARIA DB에서 활용할때

MARIA 상에서
•
ROLL UP → WITH ROLL UP
•
CUBE → WITH ROLL UP, 2개 UNION
•
GROUPING SETS → 각각 GROUP BY 한거를 UNION ALL